2018研究生数学建模成绩分析
本文共 6108 字,大约阅读时间需要 20 分钟。
2018研究生数学建模成绩分析,主要从以下几个方面进行分析 建模成绩数据来源:1. 按‘队长所在单位’统计每个学校的获奖数量,并画出柱状图展示
这里是代码的头部#coding:utf-8import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom geopy.geocoders.baidu import Baiduimport osimport timesns.set(style="whitegrid")plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体plt.rcParams['axes.unicode_minus'] = False # 解决中文字体负号显示不正常问题path='../data/'save_dir='../tmp/'data=pd.read_excel(path+'2018建模成绩汇总.xlsx')data['奖项']=data['奖项'].apply(lambda x:'一等奖'if x=='一等奖(华为)' else x)
# 按'队长所在单位'分别统计获奖数量def school_cnt(df): school_cnt_df=df[df['奖项']!='成功参与奖'][['奖项','队长所在单位']].groupby(['队长所在单位','奖项']).size().unstack() school_cnt_df['获奖数量']=school_cnt_df[['一等奖','二等奖','三等奖']].sum(axis=1) school_cnt_df.sort_values(by=['获奖数量','一等奖','二等奖','三等奖'],axis=0,ascending = False,inplace=True) school_cnt_df=school_cnt_df[['一等奖','二等奖','三等奖','获奖数量']] school_cnt_df=school_cnt_df.reset_index().rename(columns={'队长所在单位':'学校名称'}) print(school_cnt_df.head(5)) # school_cnt_df.to_excel(path+'school_cnt.xlsx',encoding='gbk') # 用柱状图给出获奖数量最多的前20个学校 plt.figure(figsize=(15, 10)).subplotpars.update(bottom=0.25) sns.barplot(x="学校名称", y="获奖数量", data=school_cnt_df.loc[0:20], palette="muted") plt.xticks(ha='right', rotation=40) plt.savefig(path+'school_cnt.png') plt.show() 用柱状图给出获奖数量最多的前20个学校
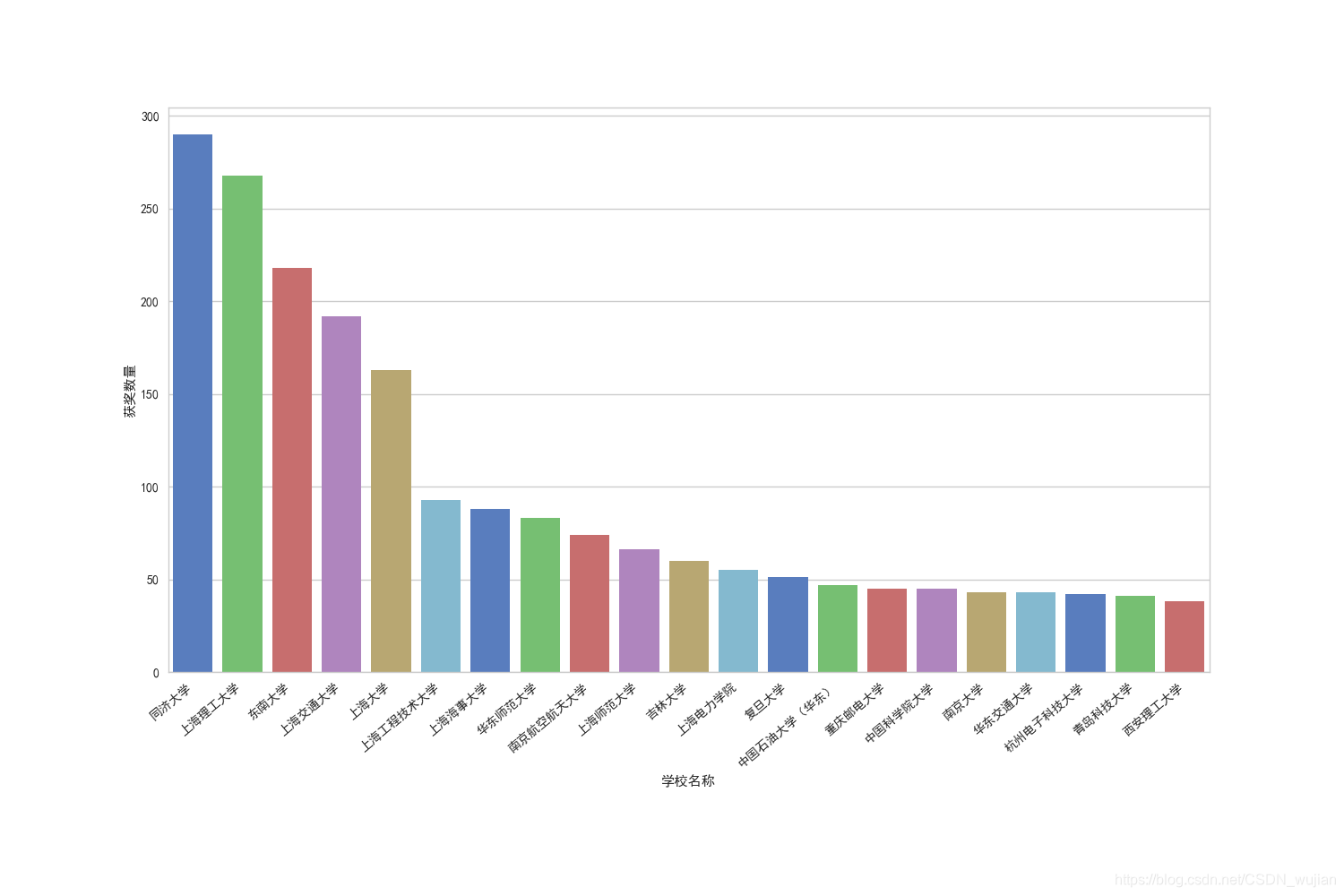 2. 按每个学校获奖人数进行统计,并画出柱状图进行展示
2. 按每个学校获奖人数进行统计,并画出柱状图进行展示 # 统计每个学校的获奖人数# 思路1:使用双层字典嵌套逐个统计# 思路2:groupbydef team_member_cnt(df): team_leader_cnt_df=df[['奖项','队长所在单位']].groupby(['队长所在单位','奖项']).size().unstack() team_member_df=team_leader_cnt_df[['一等奖','二等奖','三等奖']] team_member_cnt_df1=df[['奖项','第一队友所在单位']].groupby(['第一队友所在单位','奖项']).size().unstack() team_member_df=team_member_df.join(team_member_cnt_df1[['一等奖','二等奖','三等奖']],how='outer',rsuffix='_2') team_member_cnt_df2=df[['奖项','第二队友所在单位']].groupby(['第二队友所在单位','奖项']).size().unstack() team_member_df=team_member_df.join(team_member_cnt_df2[['一等奖','二等奖','三等奖']],how='outer',rsuffix='_3') team_member_df.rename(columns={'一等奖':'一等奖_1','二等奖':'二等奖_1','三等奖':'三等奖_1'},inplace=True) team_member_df['获奖总人数']=team_member_df.sum(axis=1) sort_cols=['获奖总人数','一等奖_1','一等奖_2','一等奖_3','二等奖_1','二等奖_2','二等奖_3','三等奖_1','三等奖_2','三等奖_3'] team_member_df.sort_values(by=sort_cols,ascending=False,inplace=True) team_member_df=team_member_df.reset_index().rename(columns={'index':'学校名称'}) print(team_member_df.head()) team_member_df.to_excel(path+'各学校获奖人数统计.xlsx',encoding='gbk',index=False) # 用柱状图给出获奖人数最多的前20个学校 plt.figure(figsize=(15, 10)).subplotpars.update(bottom=0.25) sns.barplot(x="学校名称", y="获奖总人数", data=team_member_df.loc[0:20], palette="muted") plt.xticks(ha='right', rotation=40) plt.savefig(path+'school_cnt_amount.png') plt.show()temp_df=data[data['奖项']!='成功参与奖'][['奖项','队长所在单位','第一队友所在单位','第二队友所在单位']]if __name__=="__main__": school_cnt(data) team_member_cnt(temp_df) 统计每个学校的获奖人数用柱状图展示
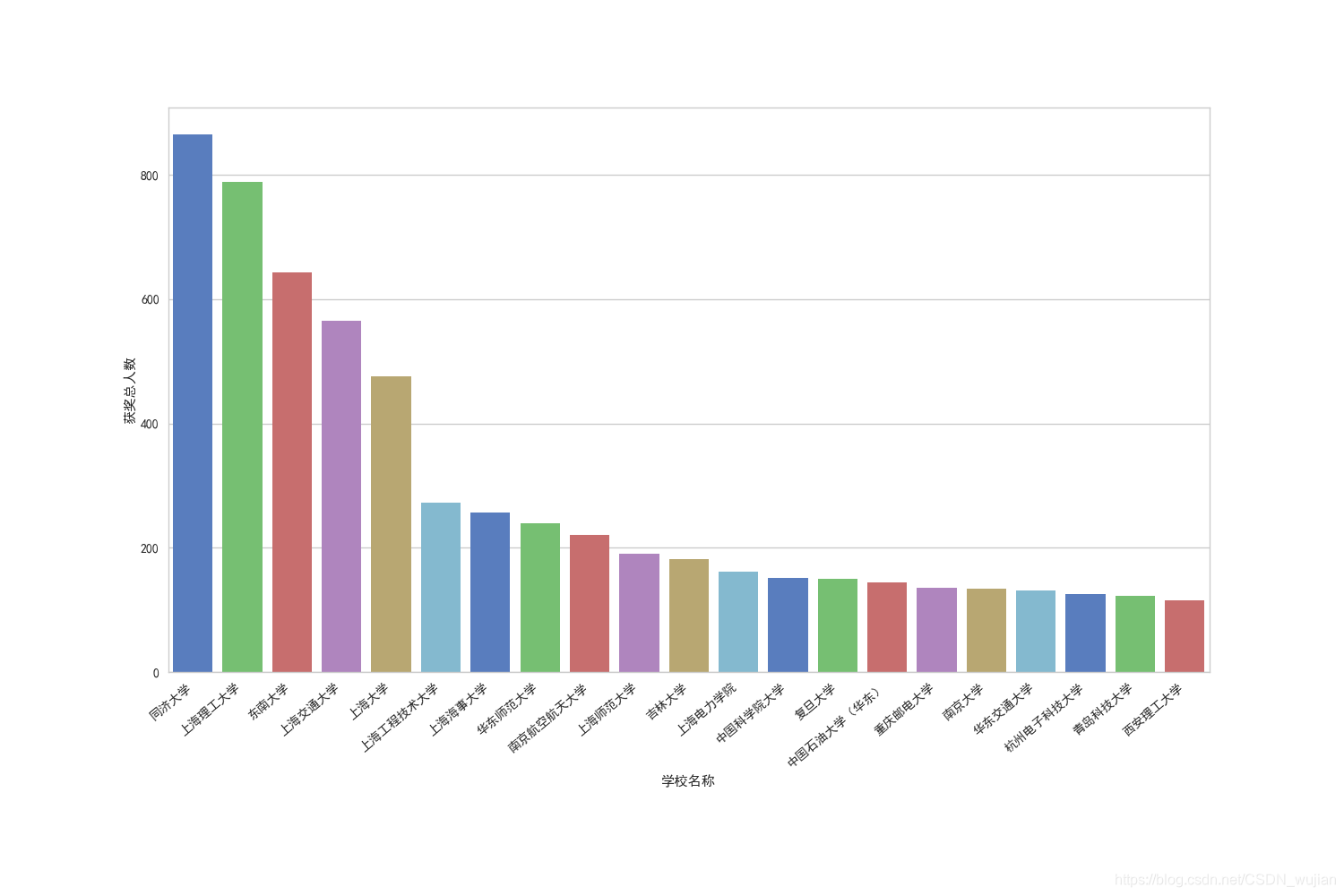 统计各个学校各个名次及次序的获奖人数信息如下:
统计各个学校各个名次及次序的获奖人数信息如下: 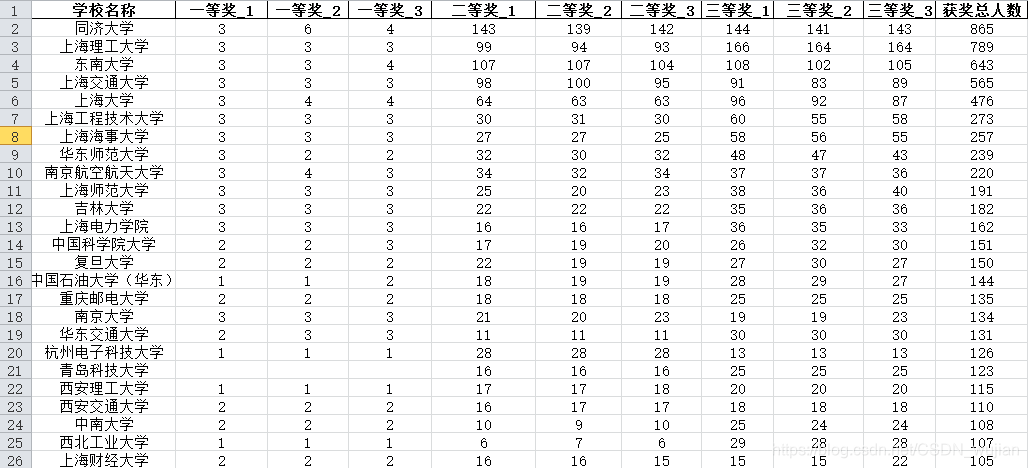
3. 分析A、B、C、D、E、F每个题的获奖数量及占比
# 分析A、B、C、D、E、F每个题的获奖数量及占比def get_question_prize_ration(df): question_df=df[['队伍编号','题号']].groupby(['题号']).count() question_df=question_df.reset_index().rename(columns={'index':'题号','队伍编号':'获奖数量'}) # prize_sum=question_df['获奖数量'].sum() question_df['获奖比例']=question_df['获奖数量']/(question_df['获奖数量'].sum()) print(question_df) question_df.to_excel(save_dir+'每题获奖数量比例.xlsx',index=False,encoding='gbk') plt.figure(figsize=(12,6)) N,width=6,0.35 ind=np.arange(N) plt.subplot(121) plt.title('A、B、C、D、E、F每个题的获奖数量') plt.bar(ind,question_df['获奖数量'],width=width) plt.ylabel('获奖数量') plt.xticks(ind,('A','B','C','D','E','F')) plt.subplot(122) plt.title('A、B、C、D、E、F题获奖比例') plt.pie(question_df['获奖比例'],labels=('A','B','C','D','E','F'),startangle=0,radius=0.8,labeldistance=0.5) plt.savefig(save_dir+'每个题的获奖数量和比例.png') plt.show() 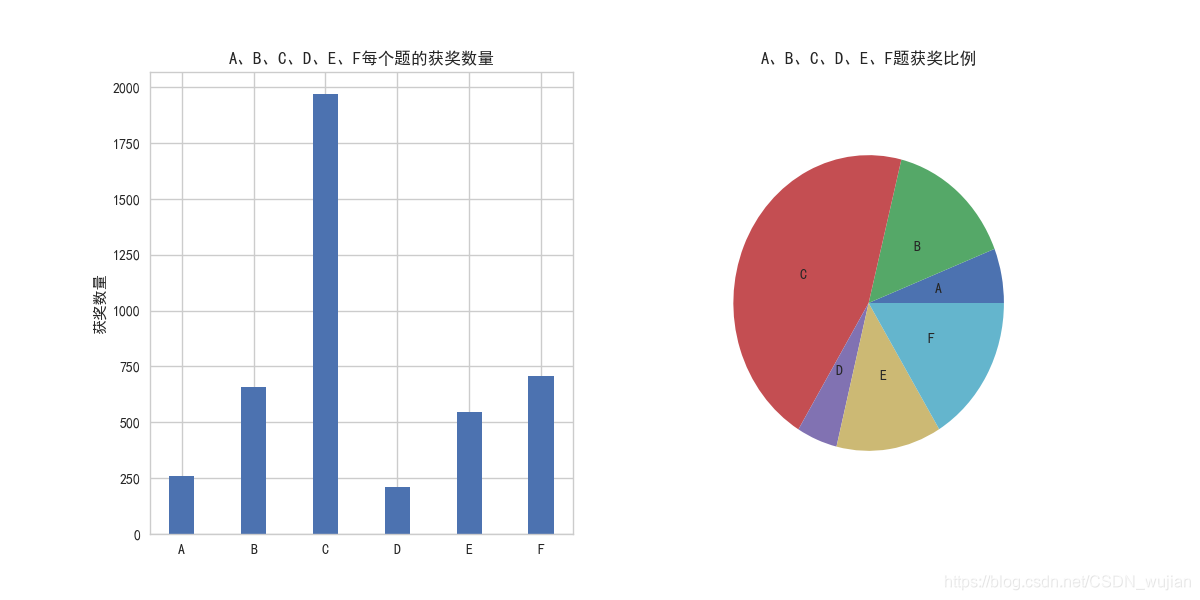
4. 计算A、B、C、D、E、F每个题获奖人数与参与人数之比,并用饼图展示
类比第3问(作者太懒,见谅)5. 按地图省份绘制每个省的参与人数热力图
类比第6问(作者太懒,见谅)6. 按地图省份绘制每个省份的获奖人数热力图
# 按地图省份绘制每个省份的获奖人数热力图# 调用百度地图API获取每个学校的经纬度信息def get_school_info(): df = pd.read_excel(save_dir+'各学校获奖人数统计.xlsx',encoding='gbk') lng_set = [] lat_set=[] for school in df['学校名称']: print(school) try: location = geolocator.geocode(school, timeout=300) lng_lat=location.raw['location'] lng,lat=lng_lat['lng'],lng_lat['lat'] print(lng,lat) lng_set.append(lng) lat_set.append(lat) except Exception as e: print(e) time.sleep(5) lng_set.append(np.nan) lat_set.append(np.nan) df['lng']=lng_set df['lat']=lat_set df=df[['学校名称','获奖总人数','lng','lat']] df.to_excel(save_dir+'school_loc_prize_nums.xlsx',encoding='gbk', index=False,float_format='%.6f') print(df.head())
# 绘制热力地图def draw_heatmap(input_path,out_path): df=pd.read_excel(input_path,encoding='gbk') df=df[df['lng']>0] rows=df.shape[0] fout=open(out_path,'w',encoding="utf-8") fout.write(''' 2018研究生建模成绩地理位置分析 ''' ) fout.close() 
 从热力图可以看出:上海地区是参加研究生数学建模的主力军,也是获奖最多的地区,其中有一个最主要的原因:上海高校多,研究生建模获奖在落沪打分时可以加不少的分数(一等奖:+10分,二等奖:+8分,三等奖:+6分)。
从热力图可以看出:上海地区是参加研究生数学建模的主力军,也是获奖最多的地区,其中有一个最主要的原因:上海高校多,研究生建模获奖在落沪打分时可以加不少的分数(一等奖:+10分,二等奖:+8分,三等奖:+6分)。 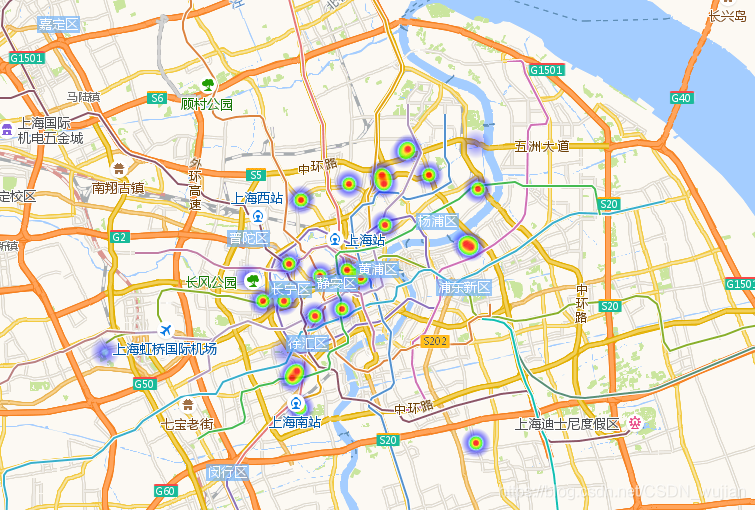 这里是整个分析代码的主函数(尾部)
这里是整个分析代码的主函数(尾部) if __name__=="__main__": school_cnt(data) temp_df=data[data['奖项']!='成功参与奖'][['奖项','队长所在单位','第一队友所在单位','第二队友所在单位']] team_member_cnt(temp_df) prize_df=data[data['奖项']!='成功参与奖'] get_question_prize_ration(prize_df) # 此处需要替换成你自己的百度地图api_key,去百度地图上申请吧 api_key = 'your-personal-key' geolocator = Baidu(api_key=api_key) get_school_info() input_path=save_dir+'school_loc_prize_nums.xlsx' out_path=save_dir+'heat_map.html' draw_heatmap(input_path,out_path)
7. 总结分析
放上一些中间过程的统计表格: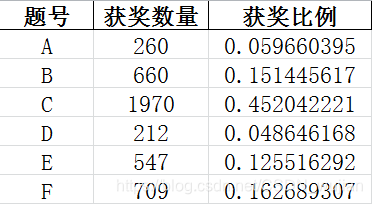
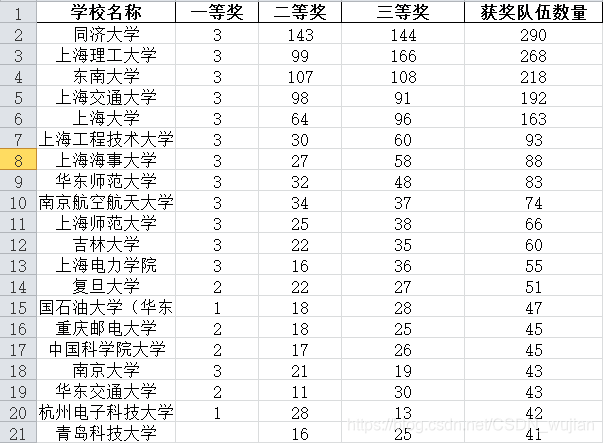
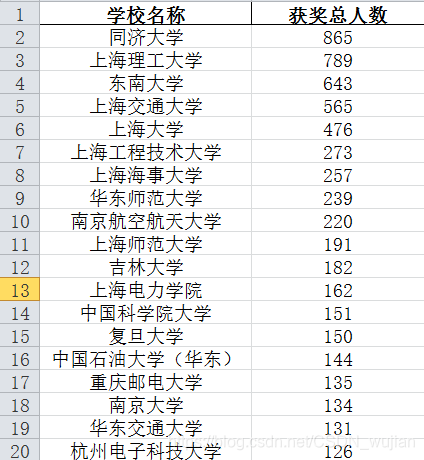
分析:
(1)随着上海落沪打分的发展,上海地区的高校参与研究生数学建模的积极性很高,积极性高于全国其他地区,获奖比例也是最高的。正常情况下参加研究生数学建建模获奖了,基本上就满足了落沪的基本要求72分,(一等奖:+10分,二等奖:+8分,三等奖:+6分,且不分个人在队伍中的排名次序)。 (2)在参与的学校中,同济大学的获奖数量是最多的,数学实力很强! (3)2018年A、B、C、D、E、F题中,C题是关于恐怖袭击事件量化分析,主要是处理数据,进行分析,容易入手,参与的人数也是做多的,获奖数量也是占到总奖数的45%左右。这也逐渐向大数据的方向发展。 (4)获奖带来的喜悦,是4天零4小时辛苦付出所换来的。不论如何,参与过得都知道过程中的辛苦,熬夜爆肝。记于:2018年11月14日
附上转载地址:http://kslrb.baihongyu.com/
你可能感兴趣的文章
java并行流
查看>>
CompletableFuture 组合式异步编程
查看>>
mysql查询某一个字段是否包含中文字符
查看>>
Java中equals和==的区别
查看>>
JVM内存管理及GC机制
查看>>
Java:按值传递还是按引用传递详细解说
查看>>
Java中Synchronized的用法
查看>>
阻塞队列
查看>>
linux的基础知识
查看>>
接口技术原理
查看>>
五大串口的基本原理
查看>>
PCB设计技巧与注意事项
查看>>
linux进程之间通讯常用信号
查看>>
main函数带参数
查看>>
PCB布线技巧
查看>>
关于PCB设计中过孔能否打在焊盘上的两种观点
查看>>
PCB反推理念
查看>>
京东技术架构(一)构建亿级前端读服务
查看>>
php 解决json_encode中文UNICODE转码问题
查看>>
LNMP 安装 thinkcmf提示404not found
查看>>